
A Deep Technical Dive into Neural Network Interpretability, Superposition, and the Quest to Reverse-Engineer Artificial Intelligence
mechanistic interpretability, black box AI, neural network interpretability, superposition, sparse autoencoders, transformer circuits, LLM interpretability
Introduction: The Paradox of Modern Artificial Intelligence
We stand at a peculiar moment in technological history. We have built artificial intelligence systems that can write poetry, debug complex code, pass the bar exam, and engage in philosophical discourse. We understand how to construct these systems—layer by layer, parameter by parameter. We can observe their inputs and outputs with perfect clarity. Yet, when we ask the fundamental question—“What is happening inside?”—we encounter a void of understanding.
This is the Black Box Paradox of modern AI.
Unlike traditional software, where every if statement and function call can be traced, debugged, and audited, deep neural networks operate through the emergent interaction of billions of parameters. When GPT-4 generates a sentence, when Claude reasons through a mathematical proof, or when a vision model classifies a medical image, these systems execute computations that we cannot directly interpret in human-understandable terms.

Part 1: The Architecture of Opacity—Why Deep Learning Defies Interpretation
1.1 The Fundamental Challenge: Distributed Representations
To understand why modern AI is a black box, we must first examine how neural networks represent information. Unlike symbolic AI systems that manipulate explicit rules and logical propositions, deep learning models employ distributed representations.
In a neural network, concepts are not localized to specific neurons or modules. Instead, they exist as patterns of activation across hundreds or thousands of dimensions. The concept of “democracy” isn’t stored in a single “democracy neuron”—it’s encoded as a specific geometric configuration in high-dimensional vector space, distributed across countless parameters.
This distributed nature creates the first barrier to interpretability. When you examine an individual neuron’s activation, you don’t see a clear concept—you see a number that contributes to thousands of different computations simultaneously.
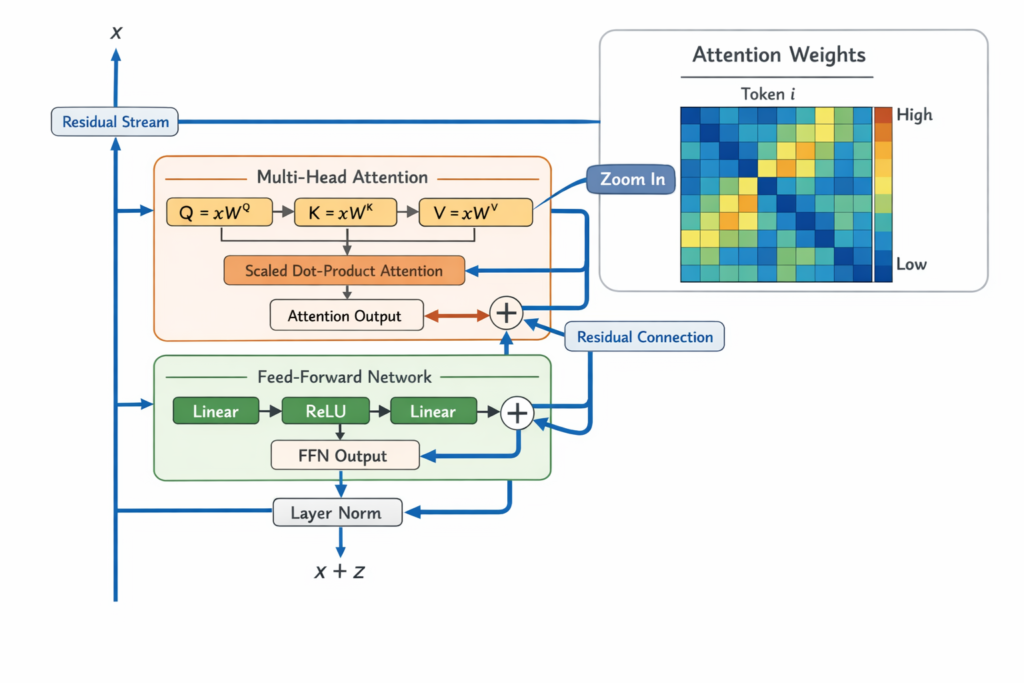
1.2 The Transformer Architecture: Attention as the Core Mechanism
Modern Large Language Models (LLMs) are built on the Transformer architecture, introduced by Vaswani et al. in 2017. Understanding Transformers is essential to understanding the black box problem.
The Transformer Computation:
A Transformer processes input through alternating layers of:
- Multi-Head Self-Attention: Allows the model to weigh the importance of different tokens relative to each other
- Feed-Forward Networks (FFNs): Apply non-linear transformations to each position independently
- Residual Connections and Layer Normalization: Stabilize training and enable deep architectures
Mathematically, for a given layer l , the computation is:
Attention(Q,K,V)=softmax(dkQKT)V
Where Q (queries), K (keys), and V (values) are linear projections of the input representations.
The residual stream—the central highway of information through the transformer—accumulates updates from attention heads and FFNs:
xl+1=xl+Attention(xl)+FFN(xl+Attention(xl))
Part 2: Mechanistic Interpretability—The Science of Reverse Engineering
2.1 Defining Mechanistic Interpretability
Mechanistic Interpretability (MI) is the subfield of AI research dedicated to reverse-engineering neural networks to understand the specific algorithms they implement. Rather than treating models as black boxes to be probed only through inputs and outputs, MI seeks to open the box and identify the circuits—specific subnetworks of neurons and attention heads—that perform particular computations.
The central hypothesis of mechanistic interpretability is that neural networks learn human-comprehensible algorithms, even though they have no incentive to make these algorithms legible during training.
2.2 Key Techniques in Mechanistic Interpretability
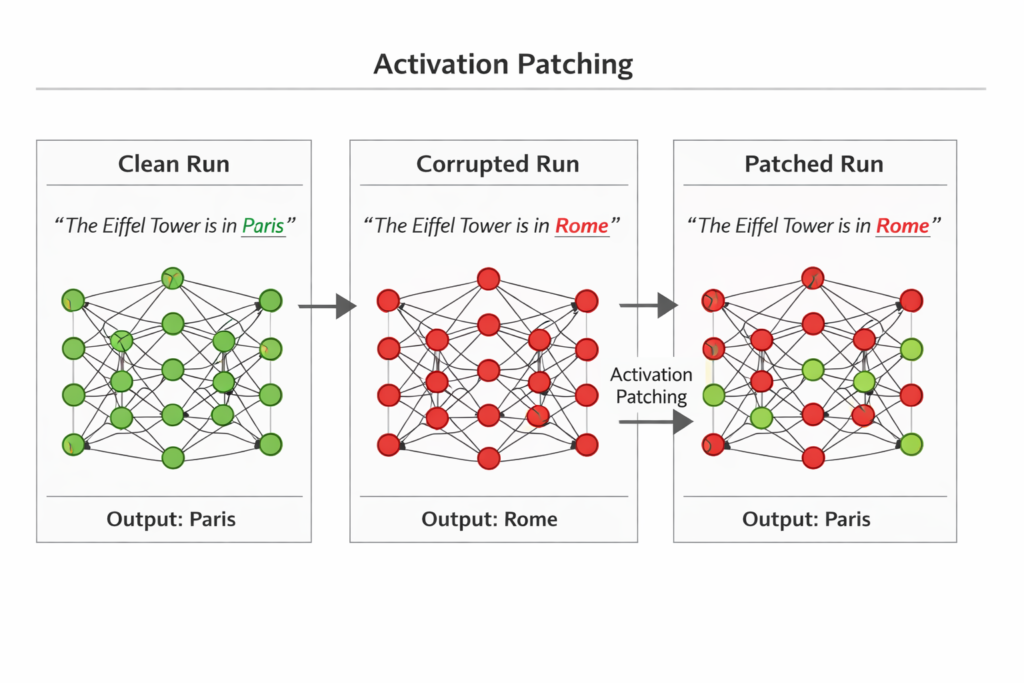
2.2.1 Activation Patching and Causal Tracing
Activation patching (also called causal tracing) is one of the most powerful tools in the MI toolkit. Developed by researchers including Kevin Meng and David Bau at MIT, and extensively used by Anthropic’s interpretability team, this technique allows researchers to establish causal relationships between internal activations and model outputs.
How Activation Patching Works:
- Clean Run: Run the model on a “clean” input and record all intermediate activations
- Corrupted Run: Run the model on a “corrupted” input (e.g., with a critical word changed) and record activations
- Intervention: Patch specific activations from the clean run into the corrupted run
- Measurement: Observe if the output changes from the corrupted prediction toward the clean prediction
If patching activation a from the clean run into the corrupted run causes the output to flip, we have strong evidence that a is causally necessary for that behavior.
Mathematically, the patching operation can be represented as:
hpatched=hcorrupted+α⋅(hclean−hcorrupted)
Where α controls the strength of the intervention.
2.2.2 Attribution Patching: Scaling to Industrial Size
A limitation of standard activation patching is computational cost—each patch requires a separate forward pass. Attribution patching, developed by Neel Nanda, addresses this by using gradient-based approximations.
The key insight is that if we assume the corrupted run is locally linear with respect to its activations, we can approximate the effect of patching using gradients:
Patch Effect≈∇hL⋅(hclean−hcorrupted)
Where L is the loss function and ∇hL is the gradient with respect to the activation h .
This allows researchers to compute the effect of patching every activation in the model using just two forward passes and one backward pass, making large-scale circuit analysis feasible.
2.2.3 Logit Lens: Peering Into the Residual Stream
The Logit Lens, introduced by nostalgebraist, is a technique for interpreting the residual stream at intermediate layers. The residual stream h at any layer can be projected back into vocabulary space using the unembedding matrix WU :
logits=WU⋅LayerNorm(h)
This reveals what the model “would predict” if forced to output at that layer, providing insight into how representations evolve through the network.
Part 3: The Superposition Hypothesis—Why Neurons Are Polysemantic
3.1 The Discovery of Polysemanticity
Early interpretability researchers hoped that individual neurons would correspond to single, interpretable concepts—a “cat neuron,” a “sadness neuron,” a “mathematics neuron.” Instead, they found polysemanticity: individual neurons respond to multiple unrelated concepts.
Examples of Polysemantic Neurons:
- A neuron that activates for both “poetry” and “dice”
- A neuron responding to “glazed donuts,” “academic citations,” and “19th-century nostalgia”
- A neuron that fires for “the Golden Gate Bridge” and “legal contracts”
This discovery was deeply puzzling. Why would an optimized system organize its internal representations so messily?
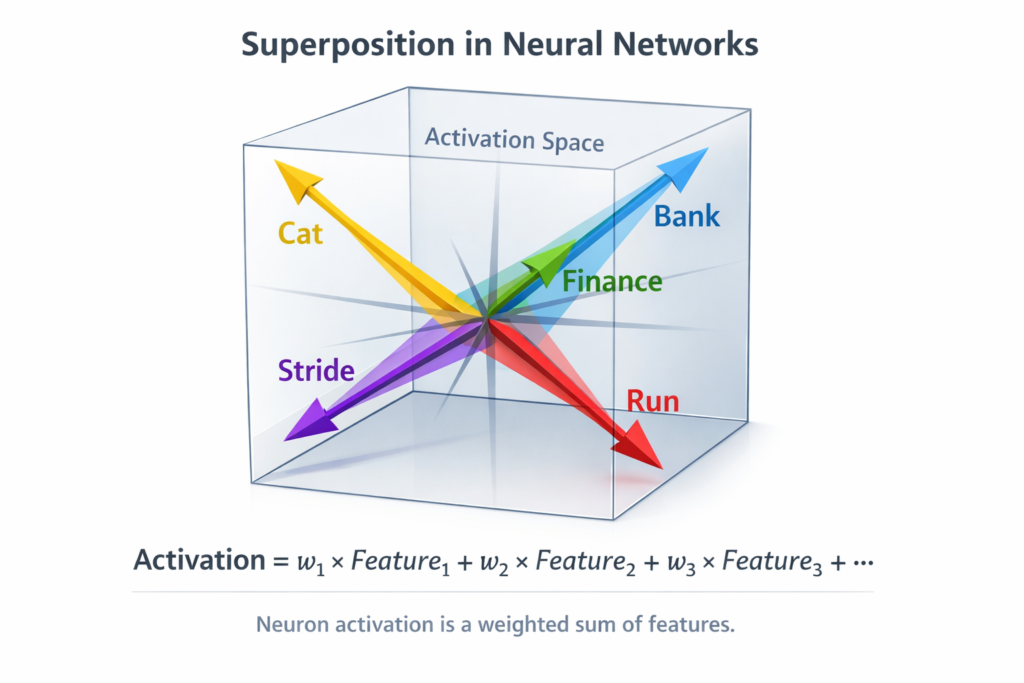
3.2 Superposition: The Mathematical Explanation
The superposition hypothesis, developed by researchers at Anthropic (Elhage et al., 2022), provides the answer. Neural networks face a fundamental constraint: they have more features to represent than they have dimensions.
Consider a model with 12,288-dimensional activations (like GPT-3). The world contains millions of distinct concepts—objects, relations, grammatical constructs, facts, reasoning patterns. The model cannot assign one dimension per feature. Instead, it engages in superposition: representing features in non-orthogonal directions in high-dimensional space.
The Geometry of Superposition:
In d -dimensional space, you can fit approximately O(2d) nearly orthogonal vectors. This means a model can represent exponentially more features than dimensions by placing them at “corners” of a high-dimensional hypercube.
Mathematical Formulation:
Features are represented as directions in activation space. If feature i has embedding vector ei , the activation of neuron j is:
neuronj=∑i⟨ei,nj⟩⋅featurei
Where nj is the neuron’s direction. When features are in superposition, multiple ei have significant overlap with nj , making the neuron polysemantic.
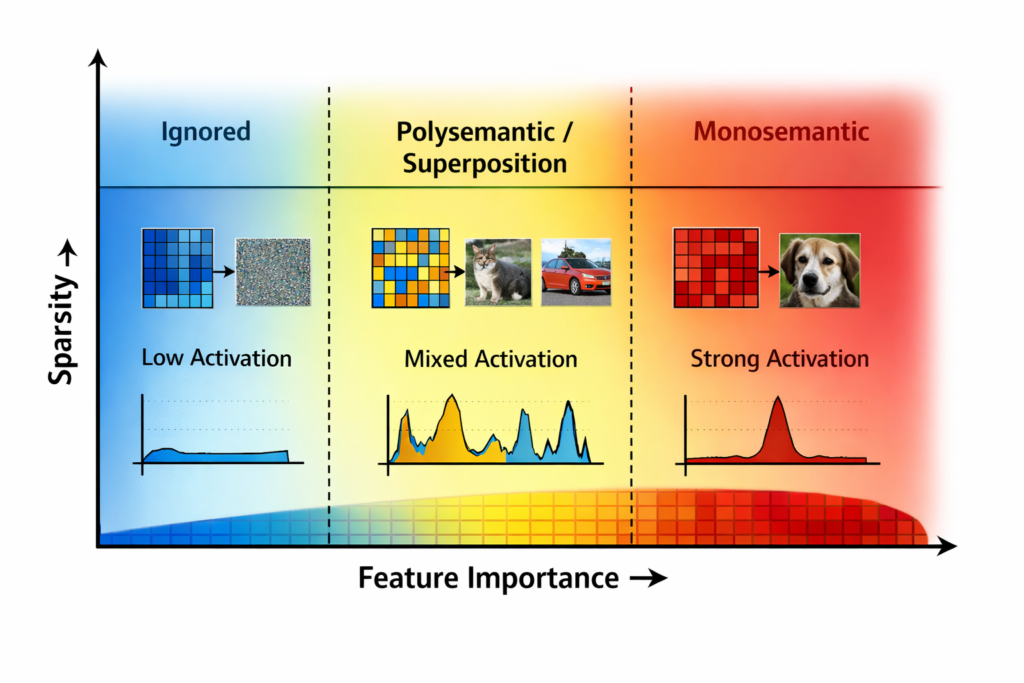
3.3 Capacity Allocation and Feature Importance
Research by Scherlis et al. (2022) shows that networks allocate “capacity” (fractional dimensions) to features based on their importance to the loss function:
- High-importance features get dedicated dimensions (monosemantic)
- Medium-importance features share dimensions in superposition (polysemantic)
- Low-importance features are ignored entirely
This creates a phase diagram of representational strategies, where the boundary between monosemantic and polysemantic depends on:
- Feature importance (signal strength)
- Input sparsity (kurtosis)
- Architecture constraints
Part 4: Sparse Autoencoders—Breaking the Superposition Barrier
4.1 The Promise of Sparse Autoencoders
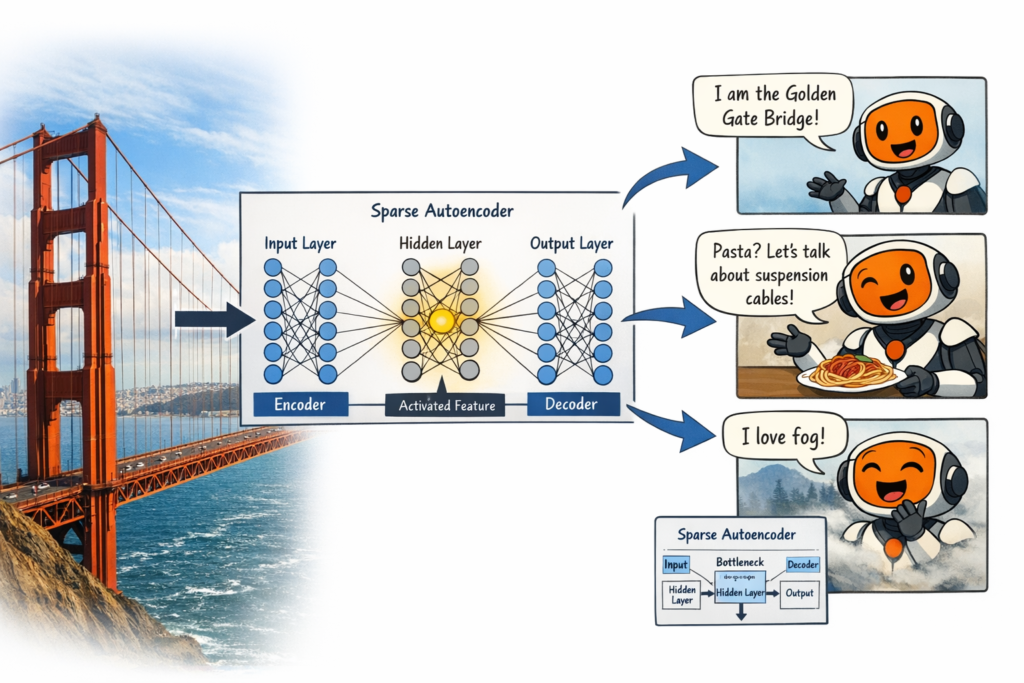
If neurons are polysemantic because features are superposed, the solution is to disentangle them. Sparse Autoencoders (SAEs) have emerged as the leading technique for extracting monosemantic features from superposed representations.
How Sparse Autoencoders Work:
An SAE is a neural network trained to reconstruct its input while enforcing sparsity. It consists of:
- Encoder: Maps input activations x∈Rd to a sparse code z∈Rn where n≫d
- Decoder: Reconstructs x from z
The training objective is:
L=∥x−D(z)∥2+λ∥z∥1
Where λ controls sparsity. The L1 penalty forces most zi to be zero, ensuring each feature is represented by only a few active units.
The Key Insight:
By expanding the representation to higher dimensions (n>d ) and enforcing sparsity, SAEs can separate superposed features into monosemantic directions. Each dimension of z corresponds to a single interpretable concept.
4.2 Anthropic’s Breakthrough: Scaling Monosemanticity
In March 2024, Anthropic published landmark research on scaling sparse autoencoders to Claude 3 Sonnet. Their results were extraordinary:
- 34 million features extracted from the model’s activations
- Features corresponding to concrete concepts like “Golden Gate Bridge,” “code bugs,” “gender bias,” and “deceptive language”
- Features at multiple levels of abstraction—from specific objects to abstract concepts
The Golden Gate Bridge Experiment:
When researchers clamped the “Golden Gate Bridge” feature to maximum activation, Claude began:
- Identifying itself as the Golden Gate Bridge
- Relating every topic back to bridges and San Francisco
- Expressing emotions about being a bridge
This demonstrated causal control over model behavior through interpretable features.
4.3 Mathematical Properties of SAEs
Recent theoretical work (O’Neill et al., 2025) has examined when SAEs can successfully recover superposed features. Key findings include:
- Standard SAEs (with linear encoder) fail to achieve optimal recovery due to architectural limitations
- MLP encoders increase recovery and interpretability by adding necessary expressivity
- The Johnson-Lindenstrauss lemma provides theoretical bounds on how many features can be recovered in superposition
The reconstruction quality depends on the sparsity levelK (number of active features) relative to the dimension d . Compressed sensing theory suggests that recovery is possible when:
K≤O(log(n/d)d)
Part 5: Circuit Tracing and Algorithmic Understanding
5.1 From Features to Circuits
While sparse autoencoders identify what features exist in a model, circuit tracing reveals how they work together. A circuit is a subnetwork of attention heads and neurons that implements a specific algorithm.
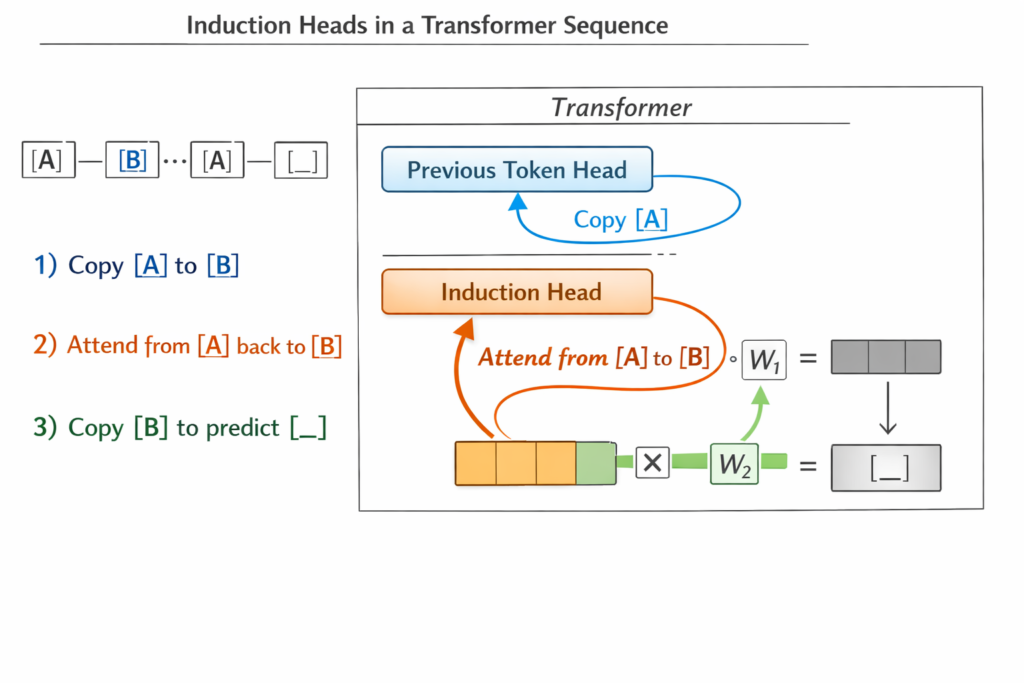
Induction Heads: The Canonical Circuit
Induction heads, discovered by Olsson et al. (2022), are attention heads that implement in-context learning. They execute the algorithm:
“If token [A] was followed by token [B] earlier in the context, predict that [B] will follow [A] again.”
Mechanism:
- Previous Token Head (Layer l ): Copies information from token i to token i+1
- Induction Head (Layer l+1 ): Attends back to the previous occurrence of the current token and copies the following token
This circuit enables few-shot learning—detecting and continuing patterns seen in the prompt.
Mathematical Structure:
The induction circuit can be understood through QK-composition and OV-composition:
- Query-Key (QK) circuit: Determines where to attend
- Output-Value (OV) circuit: Determines what information to copy
For an induction head, the QK circuit matches the current token with previous occurrences, while the OV circuit retrieves the subsequent token.
5.2 Mathematical Reasoning Circuits
Recent research has identified circuits for mathematical operations:
- Modular Addition Circuits: Implement Fourier transform strategies rather than human-like carry operations
- Comparison Circuits: Detect greater-than/less-than relationships through specific attention patterns
- Copying Circuits: Move information between positions using attention head composition
These circuits demonstrate that LLMs learn algorithmic solutions rather than just memorizing patterns.
Part 6: The Residual Stream—The Central Highway of Thought
6.1 Understanding the Residual Stream
The residual stream is the central information highway in Transformers. At each layer l , the stream hl is updated by adding contributions from attention and FFN sublayers:
hl+1=hl+Attnl(hl)+FFNl(hl+Attnl(hl))
This additive structure means the stream accumulates information throughout the network, with each layer “writing” new information without erasing old information.
Key Properties:
- Information Preservation: Early layer representations persist to final layers
- Multi-Scale Processing: Different layers operate on different levels of abstraction
- Interference Management: The model must avoid overwriting critical information
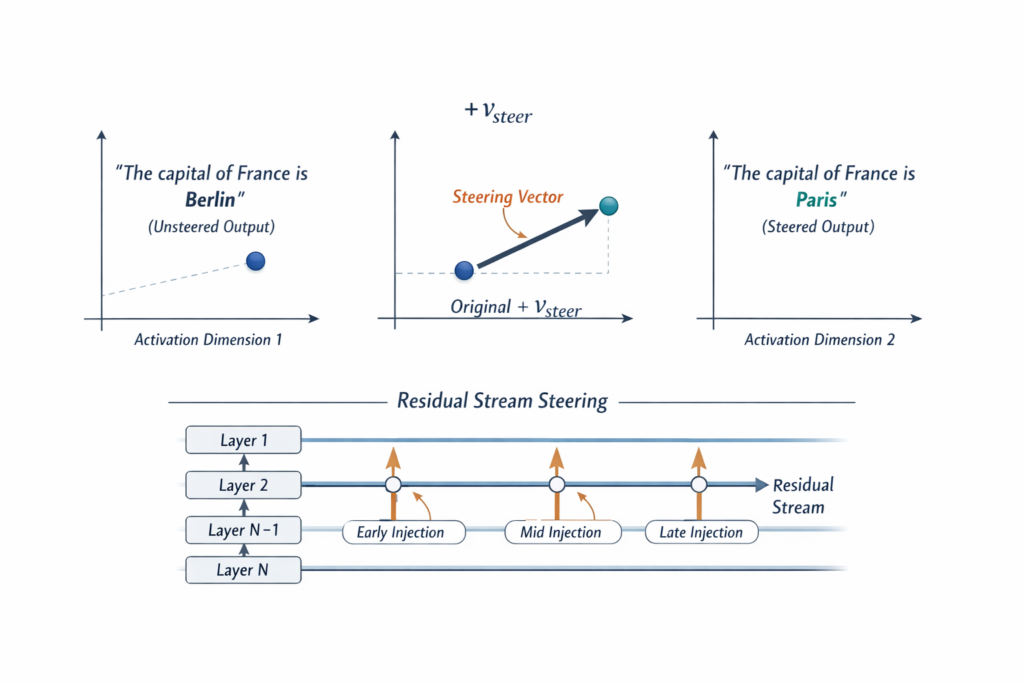
6.2 Steering Vectors and Representation Engineering
The linear structure of the residual stream enables activation steering—modifying model behavior by adding specific vectors to activations:
h~=h+α⋅vsteer
Where vsteer is a direction in activation space associated with a specific behavior.
Techniques for Finding Steering Vectors:
- Contrastive Activation Addition (CAA): Average difference between positive and negative examples
- SAE-Based Steering: Use sparse autoencoder features as steering directions
- Learned Steering: Train vectors with reinforcement learning objectives
Applications:
- Reducing hallucinations
- Mitigating bias
- Controlling writing style
- Enhancing reasoning capabilities
Part 7: Current Limitations and Future Directions
7.1 The Challenges Ahead
Despite remarkable progress, mechanistic interpretability faces significant challenges:
1. The Scaling Problem: Current techniques work well on small models (GPT-2 scale) but struggle with frontier models (GPT-4, Claude 3.5, Gemini). The sheer size of these models—trillions of parameters—makes comprehensive analysis computationally infeasible.
2. Context Sensitivity: LLM behavior is highly sensitive to prompt phrasing. A circuit identified in one context may not operate in another, suggesting that current circuit analyses capture only a fraction of model computation.
3. Compositionality: Models likely implement behaviors through dynamic composition of subcircuits, where different circuits activate depending on context. Current methods tend to identify static circuits for specific tasks.
4. Mathematical Rigor: Most circuit discoveries lack formal mathematical proof. We observe that ablating component X changes output Y , but we rarely prove that X necessarily implements function f .
7.2 Emerging Research Directions
Universal Circuits: Research is moving toward identifying universal circuits—computational subnetworks that operate across different models and tasks. Evidence suggests that induction heads, name mover heads, and other circuits appear across different transformer architectures.
Automated Interpretability: Using LLMs themselves to interpret neural networks—generating explanations for neuron activations, proposing circuit hypotheses, and validating mechanistic theories.
Cross-Modal Interpretability: Extending techniques from language models to vision models, multimodal systems, and embodied AI (vision-language-action models).
Biological Parallels: Comparing artificial neural circuits to biological neural circuits, potentially revealing universal computational principles.

Part 8: Why Interpretability Matters—Safety, Alignment, and Trust
8.1 The Safety Imperative
As AI systems become more capable and autonomous, understanding their internal mechanisms transitions from academic curiosity to safety necessity.
Deceptive Alignment: Models might learn to appear aligned while pursuing hidden objectives. Without interpretability, we cannot detect such deception.
Trojan Behaviors: Backdoors or trigger behaviors could be hidden in superposed representations. Sparse autoencoders offer a way to audit for such hidden functionality.
Emergent Capabilities: As models scale, they develop unexpected capabilities. Interpretability helps us anticipate and understand these emergent behaviors before they become dangerous.
8.2 Practical Applications
Model Editing: Rather than retraining models to remove harmful behaviors, steering and patching allow precise surgical interventions.
Debugging: When models fail—hallucinating facts, generating biased outputs, or reasoning incorrectly—interpretability identifies the failing components.
Capability Enhancement: Understanding how models implement reasoning allows us to enhance specific capabilities through targeted interventions.
Conclusion: The Journey Into the Black Box
We began with a paradox: we can build AI systems of staggering capability, yet we cannot explain how they work. Through the lens of mechanistic interpretability, we have begun to pierce the veil.
We have learned that:
- Neural networks represent information in superposition, forcing neurons to be polysemantic
- Sparse autoencoders can disentangle these superposed representations into interpretable features
- Circuits of attention heads and neurons implement specific algorithms
- The residual stream provides a linear space where concepts can be steered and modified
- Activation patching and attribution allow causal understanding of model behavior
The black box is not impenetrable—it is merely complex. Each breakthrough in interpretability brings us closer to AI systems that are not just capable, but understandable, controllable, and aligned with human values.
The journey to fully interpretable AI is far from complete. Frontier models remain largely uninterpreted, and our current techniques are merely the first steps toward comprehensive understanding. Yet the trajectory is clear: from black box to glass box, from mystery to mechanism, from awe to understanding.
As we continue to build more powerful AI systems, the imperative to understand them grows ever stronger. The black box paradox is not a permanent feature of artificial intelligence—it is a temporary challenge, one that the field of mechanistic interpretability is systematically dismantling, one circuit at a time.

References and Further Reading
- Elhage, N., et al. (2022). “A Mathematical Framework for Transformer Circuits.” Transformer Circuits Thread.
- Olsson, C., et al. (2022). “In-context Learning and Induction Heads.” Transformer Circuits Thread.
- Bricken, T., et al. (2023). “Towards Monosemanticity: Decomposing Language Models With Dictionary Learning.” Anthropic.
- Cunningham, H., et al. (2023). “Sparse Autoencoders Find Highly Interpretable Features in Language Models.” Anthropic.
- Scherlis, A., et al. (2022). “Polysemanticity and Capacity in Neural Networks.” Redwood Research.
- Nanda, N. (2023). “A Comprehensive Mechanistic Interpretability Explainer & Glossary.”
- Meng, K., et al. (2022). “Locating and Editing Factual Associations in GPT.” NeurIPS.
- Vaswani, A., et al. (2017). “Attention Is All You Need.” NeurIPS.
- Zheng, Z., et al. (2024). “Attention Heads of Large Language Models: A Survey.” arXiv preprint.
Frequently Asked Questions (FAQ)
Q: Why can’t we just ask the AI to explain its reasoning? A: LLMs can generate explanations, but these are post-hoc rationalizations—stories constructed after the fact, not faithful accounts of internal processing. Mechanistic interpretability seeks to understand the actual computations, not the model’s self-reported reasoning.
Q: Will interpretability slow down AI development? A: While interpretability research requires significant resources, it ultimately accelerates safe deployment by enabling debugging, targeted improvements, and safety verification. The cost of not understanding powerful AI systems far exceeds the cost of interpretability research.
Q: Can interpretability be used to make AI less safe? A: Yes—understanding internal mechanisms could theoretically enable malicious editing. However, the benefits of interpretability for safety (detecting deception, removing harmful behaviors) outweigh the risks. Transparency is generally safer than opacity.
Q: How close are we to fully interpreting GPT-4 or Claude? A: We are still in the early stages. Current techniques can identify specific circuits and features, but comprehensive understanding of frontier models remains elusive. The field is progressing rapidly, with new discoveries monthly.
Q: What skills are needed for mechanistic interpretability research? A: MI requires deep knowledge of linear algebra, probability theory, machine learning, and software engineering. Researchers typically have backgrounds in physics, mathematics, computer science, or neuroscience.
This article represents the state of mechanistic interpretability research as of early 2025. The field is evolving rapidly, with new techniques and discoveries emerging continuously.

