Meta Description: A comprehensive technical analysis of Speculative Decoding algorithms, covering draft-target architectures, verification mechanisms, EAGLE frameworks, mathematical foundations, and production optimization strategies for LLM inference acceleration.
Focus Keywords: Speculative Decoding, LLM inference optimization, draft model architecture, token verification, autoregressive generation, EAGLE-3, parallel decoding
Word Count: ~8,500 words | Reading Time: 35 minutes | Technical Depth: Advanced
Table of Contents
- Executive Summary
- The Sequential Bottleneck Problem
- Core Algorithmic Architecture
- The Mathematical Foundation of Speculative Sampling
- Draft Model Design Space
- Advanced Verification Mechanisms
- EAGLE Framework: Feature-Level Speculation
- Multi-Draft and Tree-Based Approaches
- Performance Analysis and Theoretical Bounds
- Production System Integration
- Future Research Directions
- Implementation Best Practices
Executive Summary
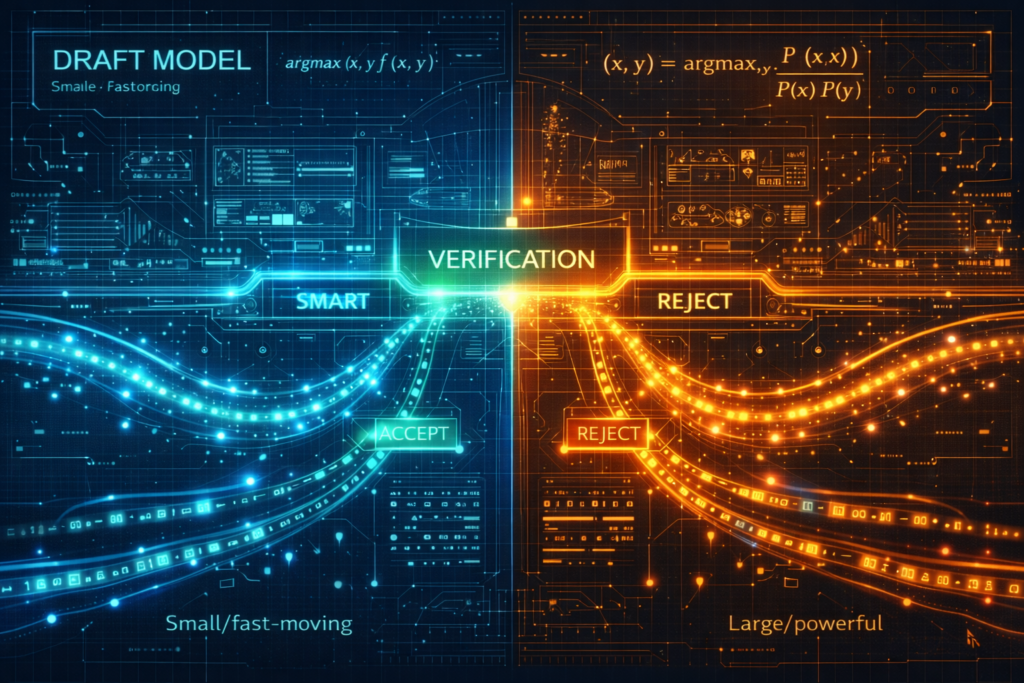
Speculative Decoding (SD) represents a paradigm shift in Large Language Model (LLM) inference optimization, addressing the fundamental sequential dependency bottleneck inherent in autoregressive generation. By leveraging the computational asymmetry between token generation (sequential, expensive) and token verification (parallel, efficient), SD achieves 2-3× latency reduction while maintaining bit-for-bit output equivalence with standard decoding.
The technique operates on a draft-verify architecture: a lightweight draft model rapidly proposes candidate token sequences, which the target model verifies in parallel through modified attention mechanisms. Critical to SD’s success is the speculative sampling algorithm, which ensures mathematical equivalence to the target model’s distribution through carefully designed acceptance-rejection criteria.
Recent advances including EAGLE-3, tree-based verification, and hardware-aware scheduling have pushed speedups beyond theoretical expectations, though production deployments reveal complex interactions between batch sizes, acceptance rates, and system overhead that demand sophisticated adaptive control systems.
The Sequential Bottleneck Problem
The Hardware Efficiency Crisis
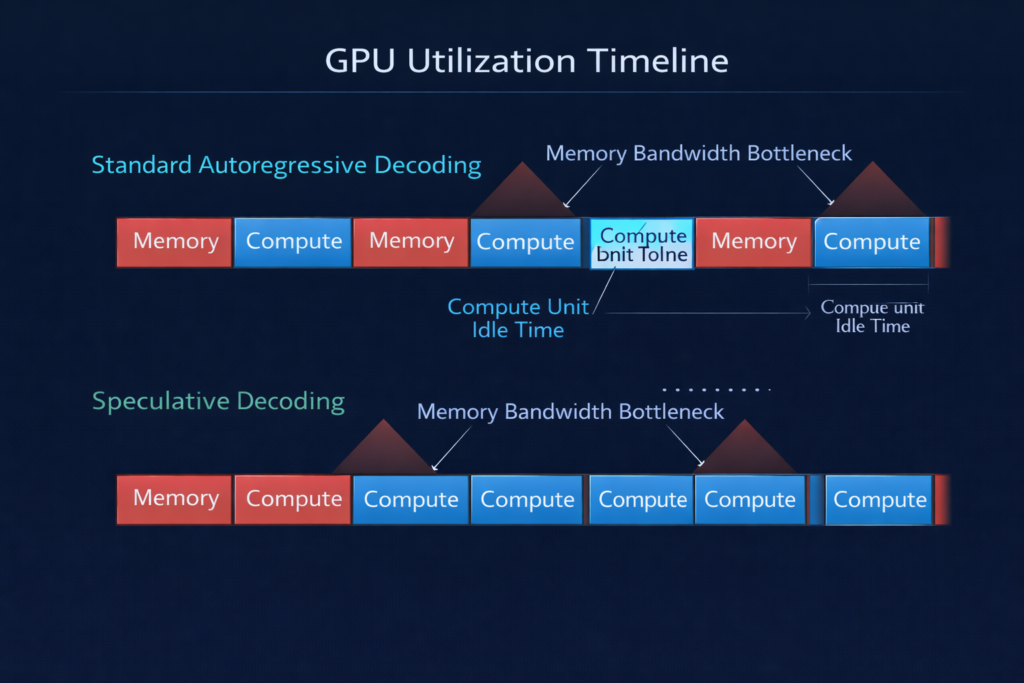
Modern LLMs face a fundamental architectural constraint: autoregressive generation requires computing token tn before token tn+1 can be predicted. This creates a memory-bandwidth-bound execution pattern where GPU compute units sit idle while waiting for memory transfers.
Consider a 70B parameter model:
- Parameter memory: 140GB (FP16)
- Memory bandwidth: 2TB/s (A100)
- Compute: 312 TFLOPS
For a single forward pass processing one token:
- Memory transfer time: ~70ms (loading all parameters)
- Compute time: ~0.5ms (actual matrix operations)
- Utilization: <1% of theoretical compute capacity
The sequential nature means we cannot amortize this memory cost across multiple tokens—each token requires reloading the full parameter set.
The Verification Asymmetry
The key insight enabling Speculative Decoding is the fundamental asymmetry in LLM operations:Table
| Operation | Sequential Steps | Parallelizable | Memory Access Pattern |
|---|---|---|---|
| Token Generation | N steps | No | Reload parameters N times |
| Token Verification | 1 step | Yes | Single parameter load |
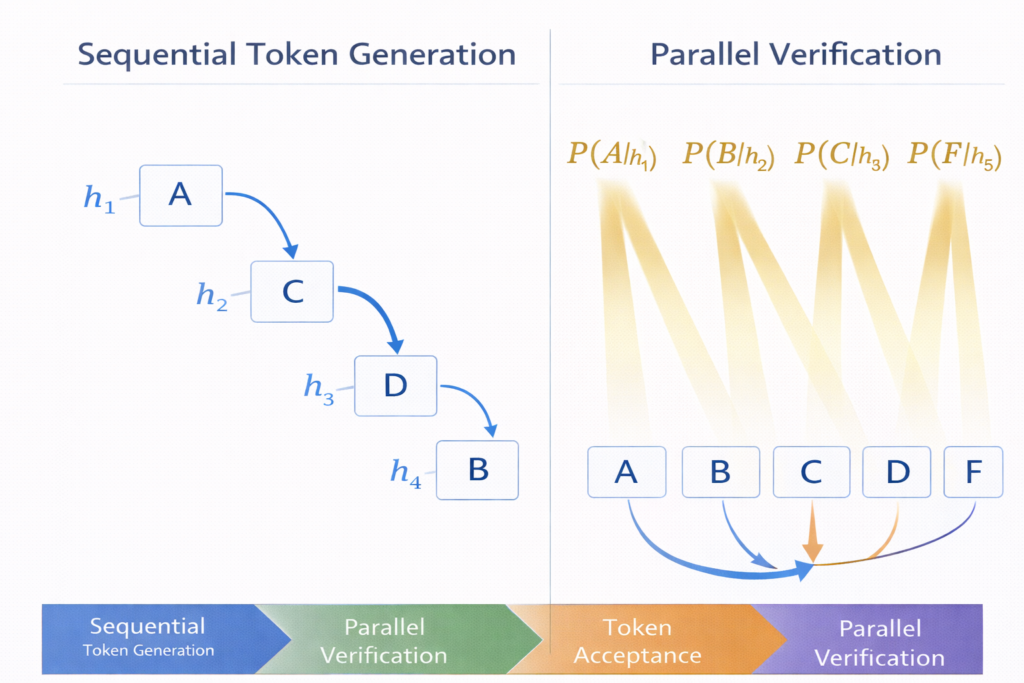
A language model can score an entire sequence [t1,t2,…,tk] in parallel, computing the probability distribution P(ti∣t<i) for all positions simultaneously using causal masking. This verification operation has identical computational cost to processing a single token, yet yields k validation results.
Core Algorithmic Architecture
The Draft-Target Paradigm
The canonical Speculative Decoding implementation employs a two-model system:
Target Model (Mtarget ): The large, high-quality model producing the final output distribution p(x∣context) . This is typically the production model (e.g., LLaMA-70B, GPT-4 class).
Draft Model (Mdraft ): A significantly smaller model (often 100×-1000× smaller) trained to approximate Mtarget ‘s behavior, producing distribution q(x∣context) .
Algorithmic Workflow
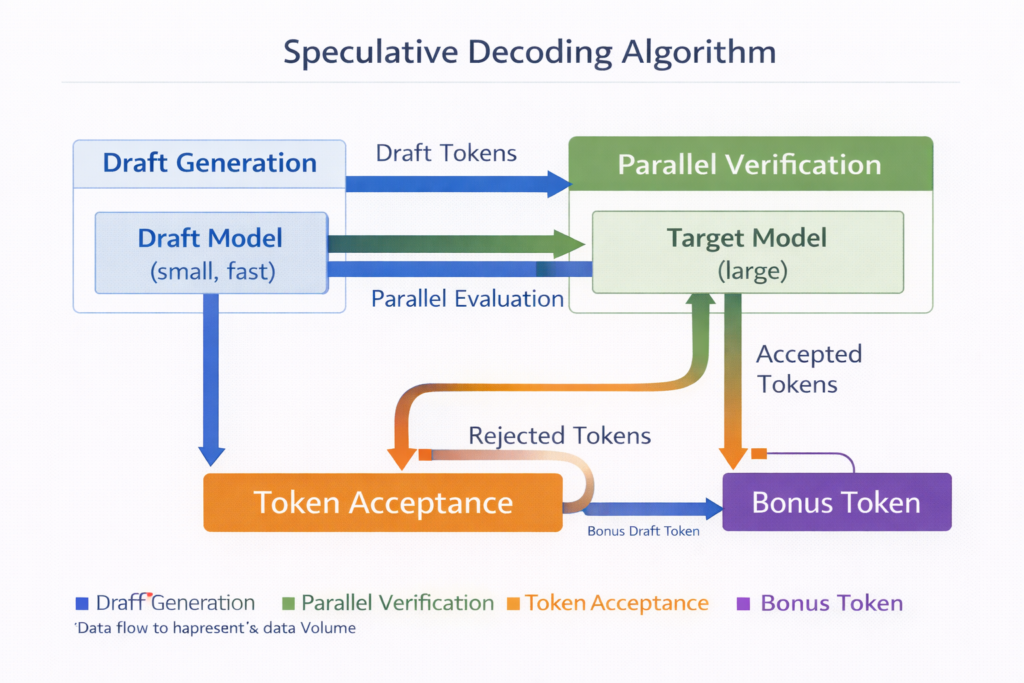
The SD loop operates through four distinct phases:
Phase 1: Draft Generation The draft model autoregressively generates K candidate tokens: x^1:K∼∏i=1Kq(xi∣context,x^1:i−1)
This phase exploits the draft model’s speed—typically 10-100× faster per token than the target.
Phase 2: Parallel Verification The target model processes the concatenated sequence [context,x^1:K] in a single forward pass, computing: pi(x)=Mtarget(x∣context,x^1:i−1)∀i∈[1,K]
Phase 3: Token Acceptance Tokens are validated sequentially using the speculative sampling criterion (detailed in Section 4). For position i :
- Accept x^i with probability min(1,qi(x^i)pi(x^i))
- If accepted: continue to i+1
- If rejected: resample from residual distribution and terminate validation
Phase 4: Bonus Token Generation Upon rejection at position j , the target model generates one additional token from the corrected distribution at position j , ensuring progress even when all drafts fail.
KV-Cache Optimization
Critical to SD efficiency is the KV-cache management:
- Prefix Cache: Keys and values for the original context are computed once and shared
- Draft Extension: Only the K new token positions require attention computation
- Verification Reuse: Accepted tokens’ KV representations are retained for the next iteration
The effective computation during verification is O(K⋅dmodel) rather than O(K⋅L⋅dmodel) where L is sequence length, due to cached prefix representations.
The Mathematical Foundation of Speculative Sampling
Distribution Preservation Theorem
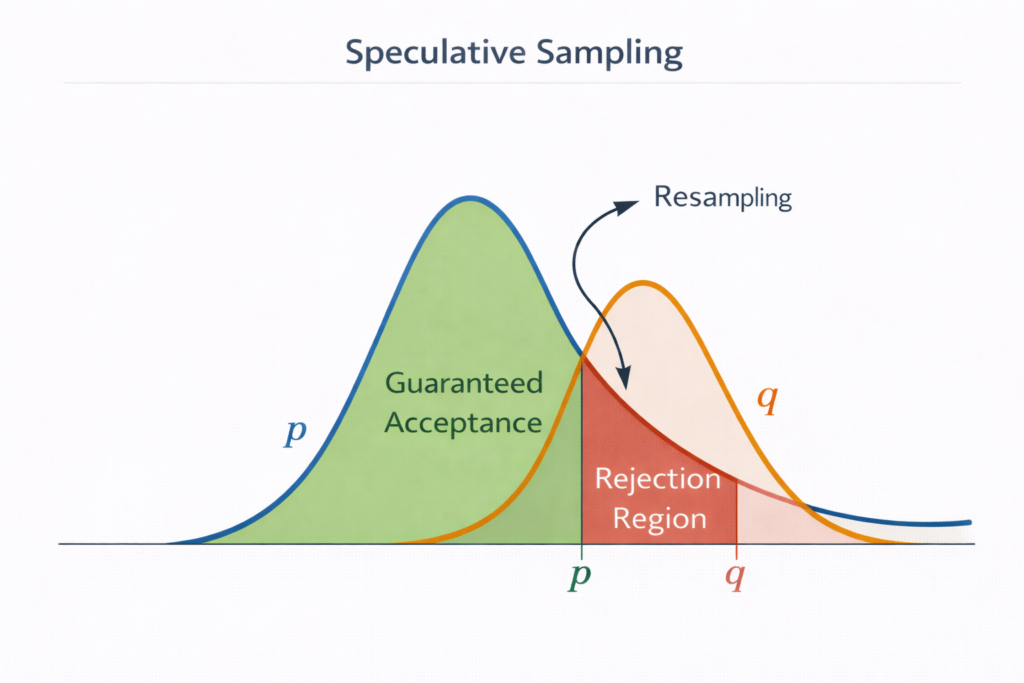
The cornerstone of Speculative Decoding is the modified rejection sampling algorithm that guarantees output equivalence to Mtarget while maximizing acceptance rates.
Theorem (Leviathan et al., 2022): The speculative sampling procedure produces samples from exactly p(x) , not an approximation.
Proof Structure:
For a single token position, consider the probability that token x appears in the final output. There are two mutually exclusive paths:
Path 1: Direct Acceptance The draft proposes x and the target accepts it: Paccept(x)=q(x)⋅min(1,q(x)p(x))=min(q(x),p(x))
Path 2: Rejection and Resampling The draft proposes some y=x , gets rejected, and x is drawn from the residual distribution.
The rejection probability for any y is: Preject(y)=q(y)⋅max(0,1−q(y)p(y))=max(0,q(y)−p(y))
The residual distribution is defined as: presid(x)=1−∑ymin(p(y),q(y))p(x)−min(p(x),q(x))=∑zmax(0,p(z)−q(z))max(0,p(x)−q(x))
The total probability of outputting x via Path 2 is: Presid(x)⋅∑yPreject(y)=Zmax(0,p(x)−q(x))⋅Z=max(0,p(x)−q(x))
Total Probability:Poutput(x)=min(p(x),q(x))+max(0,p(x)−q(x))=p(x)
Expected Acceptance Rate Analysis
The expected number of accepted tokens per iteration is: E[accepts]=∑i=1K∏j=1iαj
Where αj=Ex∼q[min(1,q(x)p(x))] is the per-position acceptance probability.
Under the assumption of token independence (simplified model): E[accepts]≈1−αα(1−αK)
The optimal draft length K∗ maximizes throughput: K∗=argmaxKTdraft(K)+TverifyE[accepts]+1
Where Tdraft(K) is the time to generate K draft tokens and Tverify is the constant verification time.
Temperature-Adjusted Sampling
For temperature T , the distributions become: pT(x)=∑yexp(zp(y)/T)exp(zp(x)/T) qT(x)=∑yexp(zq(y)/T)exp(zq(x)/T)
The acceptance criterion generalizes to: Accept with probability min(1,qT(x)pT(x))=min(1,exp(Tzp(x)−zq(x)+logZq−logZp))
At T→0 (greedy decoding), acceptance becomes deterministic: accept if argmaxp=argmaxq .
Draft Model Design Space
Architectural Trade-offs
Research by Yan et al. (2023) reveals that draft model performance in SD does not correlate strongly with standard language modeling perplexity. Instead, three factors dominate:
1. Latency Characteristics
- Depth vs. Width: Shallow-wide models (few layers, many heads) often outperform deep-narrow models despite similar parameter counts
- Memory Footprint: Models fitting in L2 cache achieve 10× better tokens/sec than those requiring HBM access
- Batch Efficiency: Single-token inference favors specific architectural choices different from training-optimal designs
2. Alignment with Target The draft model must approximate not just the target’s distribution but its ranking of tokens. Two models with identical perplexity can yield vastly different SD speedups based on top-k agreement rates.
3. Training Strategy
- Distillation: Training on target model outputs (logit matching) rather than ground truth tokens
- Sequence-Level: Optimizing for acceptance rate rather than per-token accuracy
- Online Adaptation: OSD (Online Speculative Decoding) continuously distills during inference
Hardware-Efficient Draft Architectures
Yan et al. proposed “NoFT-Wide” architectures specifically optimized for SD:Table
| Model | Layers | Hidden Dim | Heads | Parameters | Relative Speed |
|---|---|---|---|---|---|
| Standard OPT | 24 | 1024 | 16 | 350M | 1.0× |
| NoFT-Wide-350M | 4 | 2048 | 56 | 350M | 2.8× |
| NoFT-Wide-796M | 5 | 2560 | 64 | 796M | 3.2× |
The key insight: reducing layer count minimizes memory access while increasing width maintains representational capacity.
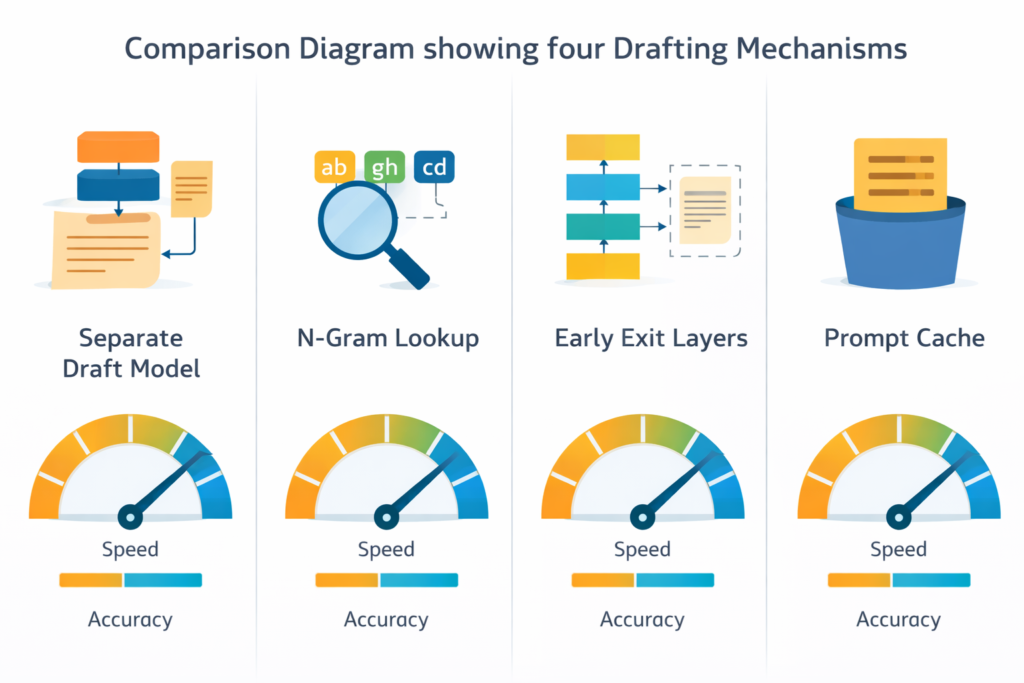
Alternative Drafting Mechanisms
N-gram Drafting: Uses cached n-gram statistics from recent context, zero computational cost but limited to repetitive patterns.
Prompt Lookup Decoding: Matches current context against previous generations in the same session, effective for long-form content with repeated references.
Early Exit Drafting: Uses intermediate layers of the target model itself as the draft mechanism, eliminating model switching overhead but with limited speedup potential (typically 1.5-2×).
Advanced Verification Mechanisms
Linear Verification with Modified Sampling
The standard approach validates tokens sequentially. However, Block Verification and MTAD (Multi-Token Acceptance Decoding) improve upon this by examining joint probability distributions:
Block Verification: Instead of independent token checks, verify the chain as a conditional probability: Paccept(x^1:K)=∏i=1Kmin(1,q(x^i∣x^<i)p(x^i∣x^<i))
This maintains the same expected acceptance while reducing variance in accepted lengths.
Tree-Based Verification (SpecInfer/EAGLE-2)
Rather than verifying a single draft sequence, tree-based methods construct and verify multiple candidate paths simultaneously.
Tree Construction: The draft model generates a tree of possibilities where each node represents a token and branches represent alternative continuations. For a tree with branching factor b and depth d , there are O(bd) potential sequences.
Tree Attention Masking: SpecInfer introduced specialized attention masks allowing the target model to verify all tree nodes in parallel while respecting causal dependencies. The attention mask M is defined as: Mij={10if node j is ancestor of node i or i=jotherwise
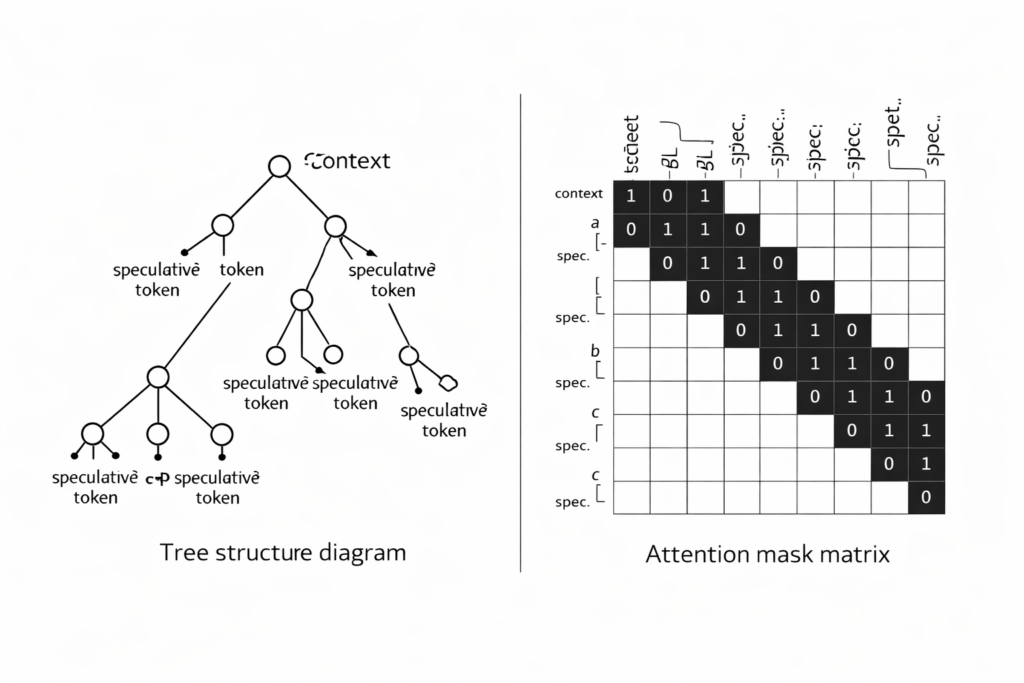
Verification Complexity: Tree verification requires O(N⋅dmodel) computation where N is total nodes, but yields O(N) validation decisions, amortizing the forward pass cost across many candidates.
Multi-Draft Speculative Decoding (MDSD)
MDSD generates multiple independent draft sequences and selects the best path:
- Generatem independent draft sequences of length K
- Verify all m×K tokens in parallel (if tree-structured) or m separate verifications
- Select the longest accepted prefix across all drafts
The probability of accepting at least k tokens increases with m : P(accept≥k)=1−(1−αk)m
However, verification cost grows with m , creating an optimization problem: m∗=argmaxmTverify(m)E[maxiacceptsi]
EAGLE Framework: Feature-Level Speculation
EAGLE Architecture
EAGLE (Extrapolation Algorithm for Greater Language-Model Efficiency) eliminates the separate draft model entirely, instead using a lightweight “EAGLE head” attached to the target model’s hidden states.
Key Innovation: Rather than predicting tokens from raw text, the EAGLE head predicts the next hidden state given current hidden states: h^t+1=EAGLEHead(ht,xt,post) x^t+1=argmax(Wlm⋅h^t+1)
Where Wlm is the target model’s existing language modeling head.
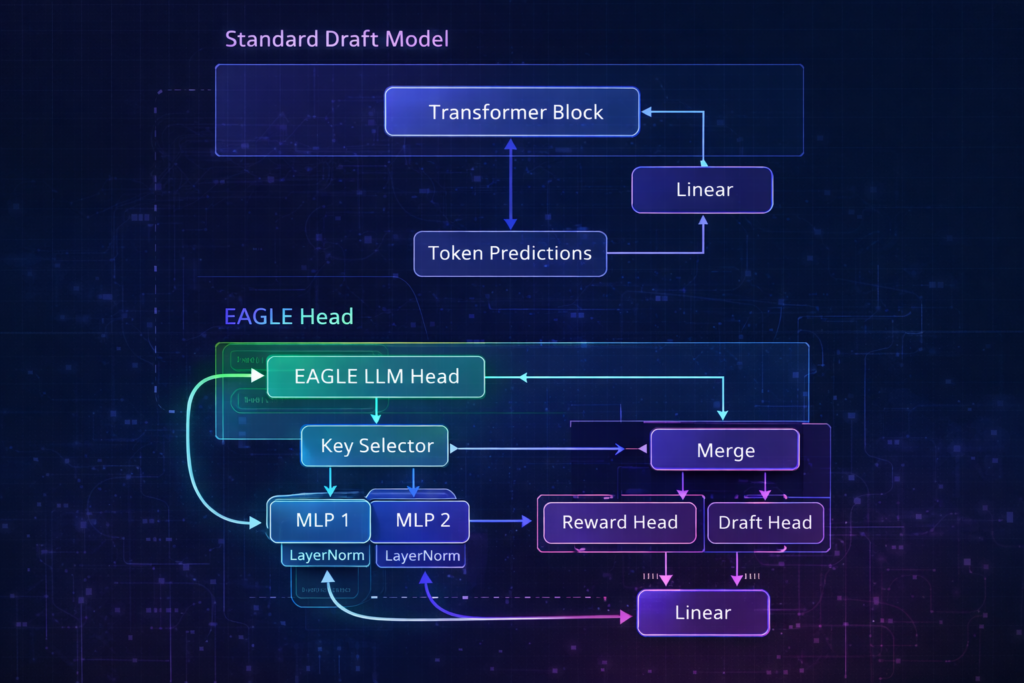
EAGLE-3: Multi-Scale Feature Fusion
EAGLE-3 advances this by incorporating features from multiple layers of the target model:
hfused=Fusion([h(L/4),h(L/2),h(3L/4),h(L)])
Where h(l) represents hidden states from layer l of the target model.
This multi-scale representation captures:
- Low-level features (early layers): Syntax, local patterns
- Mid-level features: Semantic relationships
- High-level features (late layers): Abstract concepts, reasoning
Training Objective: EAGLE heads are trained to minimize the expected verification loss: L=Ex∼ptarget[∥hEAGLE(x)−htarget(x)∥2+λ⋅CE(x^,xtrue)]
Dynamic Draft Tree (EAGLE-2)
EAGLE-2 introduced context-aware tree construction where the draft head evaluates its own confidence during generation:
Confidencet=maxxpEAGLE(x∣ht)
If confidence drops below threshold θ , the tree stops expanding that branch. This creates adaptive depth trees where predictable text generates long chains and uncertain contexts trigger early verification.

Multi-Draft and Tree-Based Approaches
Sequoia: Hardware-Aware Tree Optimization
Sequoia formalizes the tree construction as an optimization problem given hardware constraints:
Objective: Maximize expected accepted tokens per unit time maxTTverify(T)+Tdraft(T)E[accepts∣T]
Subject to:
- Memory constraints: ∣T∣⋅dmodel≤Mavailable
- Compute constraints: FLOPs(T)≤Cbudget
Where T represents the tree topology (branching factors at each level).
Optimal Tree Structure: Research shows that non-uniform trees (varying branching factor by depth) often outperform uniform trees. Typically:
- Root level: Higher branching (explore diverse options)
- Deep levels: Lower branching (exploit high-confidence paths)
OPT-Tree: Structure Search
OPT-Tree uses dynamic programming to find optimal tree structures:
- Profile target model’s acceptance rate distribution P(accept∣position,context)
- Model verification cost as function of tree size and shape
- Optimize using constrained dynamic programming: C(n)=mink{C(n−k)+Cost(k)−Benefit(k)}
Where n is total nodes, k is nodes at current depth.
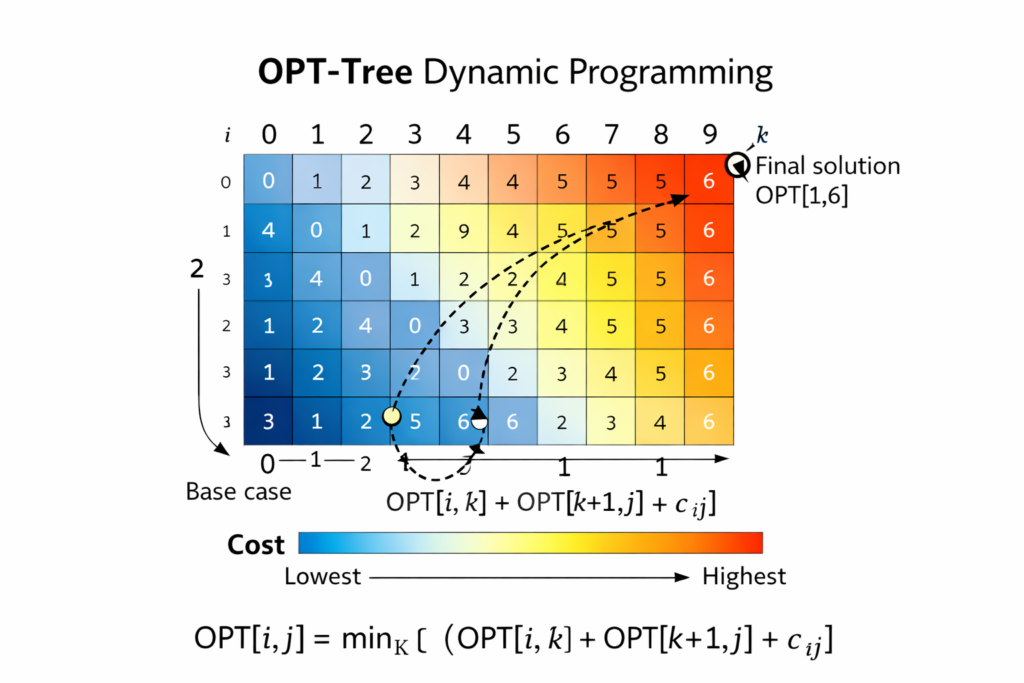
Parallel Verification Strategies
Layer-wise Verification: DSBD (Dynamic Speculative Beam Decoding) verifies tree levels sequentially, allowing early termination if upper levels fail.
Speculative Beam Search: Combines beam search with speculation—maintain k beams, each with speculative extensions, verify all beams’ extensions in parallel.
Performance Analysis and Theoretical Bounds
Throughput Model
The analytical throughput of speculative decoding is:Tput=⎩⎨⎧ttargetd+tdraftdTARttargetd+tdraftd1if TAR>1if TAR≤1
Where:
- TAR = Token Acceptance Rate (average accepted tokens per iteration)
- ttargetd = Target model verification time
- tdraftd = Draft model generation time for K tokens
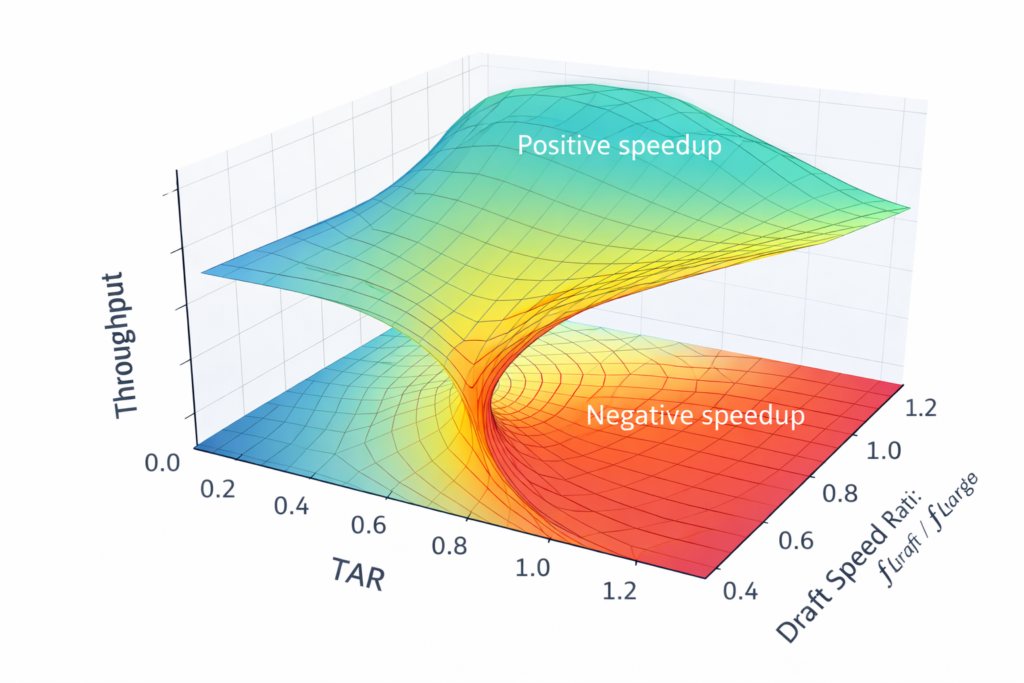
Theoretical Upper Bound
Liu et al. (2025) established the theoretical maximum speedup:
Smax=1−α+ttargettdraft1
Where α is the per-token acceptance probability.
For α→1 (perfect draft model) and tdraft→0 (infinitely fast draft): Smax→∞ (in practice limited by verification parallelism)
Real-world systems achieve 40-60% of this bound due to:
- Verification overhead: Tree attention adds computational cost
- Memory contention: Draft and target compete for bandwidth
- Batching effects: SD benefits decrease with larger batch sizes
- Acceptance variance: Real acceptance rates vary by position and context
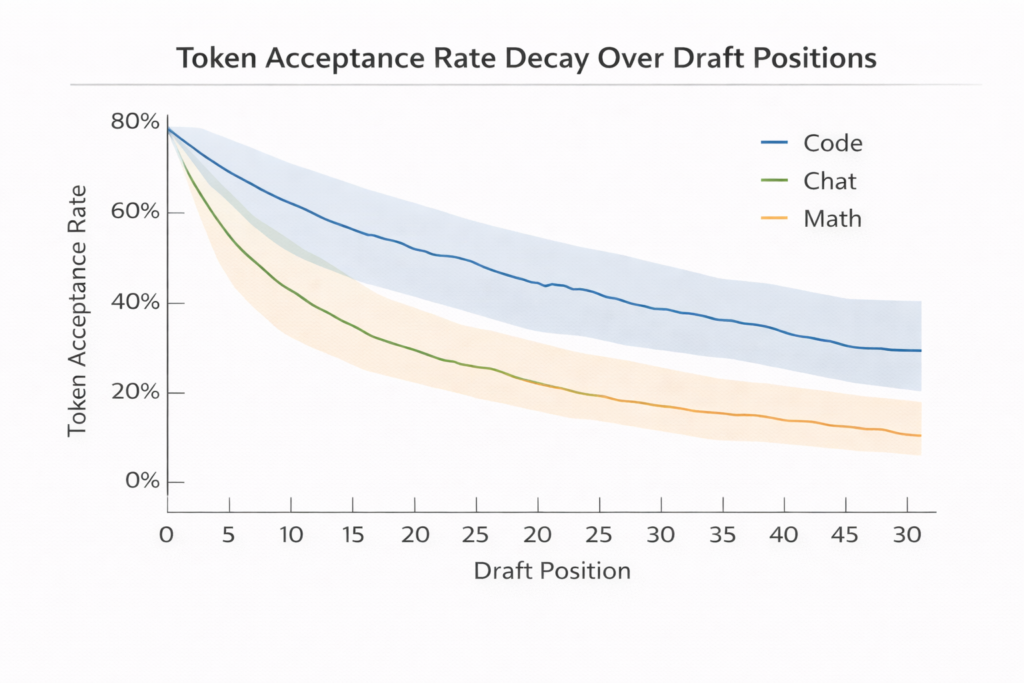
Empirical Performance Characterization
Dataset Dependence:
- Code generation: High acceptance (0.7-0.9) due to deterministic patterns
- Creative writing: Lower acceptance (0.4-0.6) due to high entropy
- Factual QA: Medium acceptance (0.5-0.7) with high variance
Position Effects: Acceptance rates typically follow a decay pattern: αi=α0⋅γi
Where γ≈0.9 and i is position in draft sequence. Early tokens match well; later tokens diverge as uncertainty compounds.
Batch Size Interactions
SD provides maximum benefit at batch size = 1. As batch size increases:
- Baseline throughput improves (better GPU utilization)
- SD overhead increases (draft generation becomes bottleneck)
- Acceptance rates may decrease (diverse contexts harder to predict)
The crossover point where SD becomes beneficial typically occurs at batch sizes < 8 for 70B class models.
Production System Integration
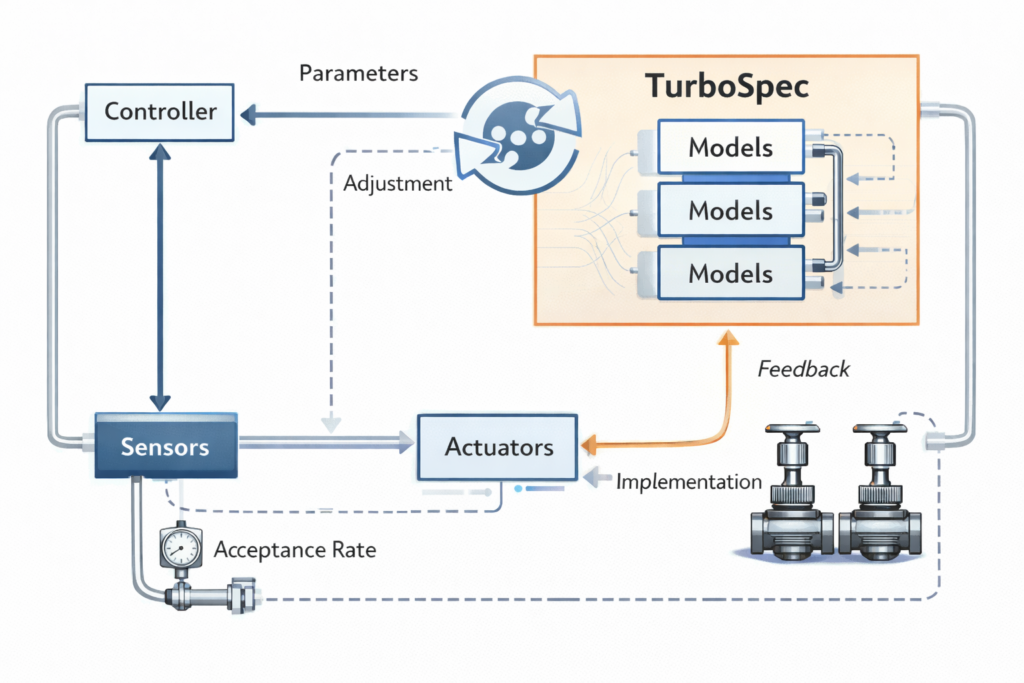
TurboSpec: Adaptive Control System
Production deployments require dynamic adaptation to changing conditions. TurboSpec introduces closed-loop control:
Goodput Metric:Goodput=Wall Clock TimeTokens Successfully Generated
Control Mechanisms:
- Speculative Depth Control: Adjust K based on observed acceptance rates
- Draft Model Selection: Switch between multiple draft models by domain
- Batching Policy: Dynamically balance inter-request batching vs intra-request speculation
vLLM Integration Challenges
The “Speculative Decoding: Performance or Illusion?” study (Liu et al., 2025) revealed critical production considerations:
Verification Dominance: In production engines, target model verification dominates execution time (60-80% of total), contrary to theoretical models assuming draft generation as bottleneck.
Acceptance Variability: Acceptance length varies markedly across:
- Token positions (early vs late in sequence)
- Request types (different prompt patterns)
- System load (affects draft model caching)
Optimization Opportunities:
- Selective Verification: Skip verification for high-confidence drafts
- Adaptive Trees: Expand tree only where uncertainty exists
- Async Drafting: Generate next draft while verifying current
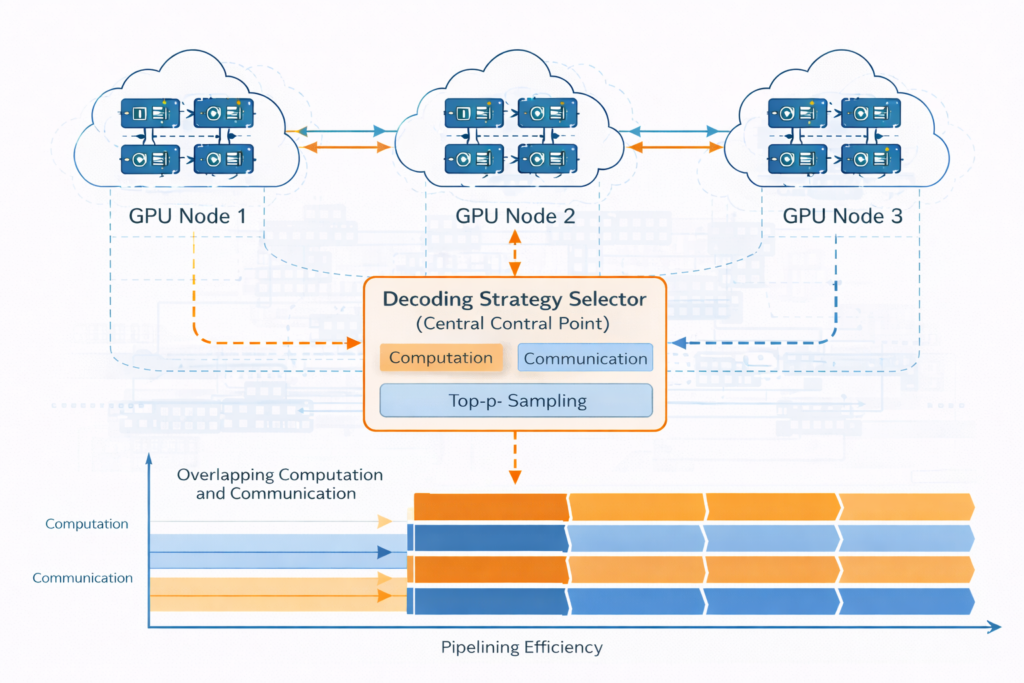
Decentralized Speculative Decoding (DSD)
For distributed inference across multiple nodes:
Communication-Computation Overlap: DSD turns network latency into useful computation by:
- Pipelining: Draft generation on node A while node B verifies previous batch
- Parallel Verification: Distribute tree branches across nodes
- Adaptive Thresholds: Adjust acceptance criteria based on network conditions
Cost Model:Ttotal=max(Tcompute,Tnetwork)−overlap
Where overlap is maximized through careful scheduling.
Future Research Directions
Learned Verification
Current verification uses exact probability comparison. Learned verification could:
- Train a lightweight classifier to predict acceptance without full forward pass
- Use embedding similarity for early rejection
- Implement cascade verification (cheap check → expensive check)
Speculative Training
Rather than training draft models to mimic target outputs, train both jointly: Ljoint=Ltarget+λ⋅Ldraft+μ⋅Lacceptance
This optimizes for end-to-end throughput rather than intermediate accuracy.
Quantum-Inspired Sampling
Exploring quantum computing concepts for verification:
- Grover’s algorithm for fast token search in probability space
- Quantum superposition to evaluate multiple draft paths simultaneously
- Amplitude amplification to boost acceptance probabilities
Neuromorphic Drafting
Custom hardware for draft model execution:
- In-memory computing for attention mechanisms
- Spiking neural networks for ultra-low-latency drafting
- Optical computing for massive parallel verification

Implementation Best Practices
Draft Model Selection Guide
| Target Model | Recommended Draft | Expected Speedup | Use Case |
|---|---|---|---|
| 7B | N-gram / Prompt lookup | 1.2-1.5× | Chat, simple QA |
| 13B | 1B parameter model | 1.8-2.2× | General purpose |
| 70B | 7B parameter model | 2.5-3.0× | Complex reasoning |
| 400B+ | EAGLE-3 head | 2.0-2.8× | Production serving |
Hyperparameter Tuning
Draft Length (K ):
- Start with K=4 for general text
- Increase to K=8 for code/repetitive content
- Decrease to K=2 for creative/high-entropy content
Temperature Adjustment:
- At T<0.5 : Use longer drafts (higher acceptance)
- At T>0.8 : Use shorter drafts or disable SD
Tree Branching:
- For EAGLE-2/3: Use adaptive depth (confidence threshold 0.9)
- For static trees: Use depth 3-4, branching factor 2-3
Monitoring and Debugging
Key Metrics:
- Acceptance Rate (AR): Target > 0.6 for positive speedup
- Draft Efficiency: Tokens generated / time spent drafting
- Verification Overhead: Percentage of time in target forward pass
- End-to-End Latency: User-perceived generation speed
Common Pitfalls:
- Draft too slow: If tdraft>0.3⋅ttarget , reduce draft size or simplify architecture
- Poor alignment: If AR < 0.4, retrain draft on target outputs
- Memory pressure: If GPU OOM, reduce batch size or tree width
Conclusion
Speculative Decoding represents a fundamental advancement in LLM inference efficiency, transforming the sequential bottleneck into a parallel verification opportunity. The technique’s mathematical elegance—preserving exact output distributions while achieving substantial speedups—makes it uniquely valuable in production environments where quality cannot be compromised.
The evolution from simple draft-target architectures to sophisticated feature-level speculation (EAGLE) and hardware-aware tree optimization demonstrates the depth of innovation in this space. However, production deployments reveal that theoretical speedups are often constrained by system-level factors: verification overhead, batching dynamics, and acceptance variability.
Future advances will likely focus on learned verification mechanisms, adaptive control systems, and specialized hardware—further closing the gap between theoretical potential and practical performance. For practitioners, the key is careful tuning of draft model architecture, speculative depth, and verification strategy to match specific workload characteristics.
As LLMs continue scaling, Speculative Decoding transitions from optimization to necessity, enabling responsive user experiences even with trillion-parameter models. The techniques described here provide the foundation for the next generation of efficient, scalable AI systems.
References and Further Reading
- Leviathan, Y., Kalman, M., & Matias, Y. (2022). Fast inference from transformers via speculative decoding. ICML.
- Stern, R., Shazeer, N., & Uszkoreit, J. (2018). Blockwise parallel decoding for deep autoregressive models. NeurIPS.
- Miao, X., et al. (2023). SpecInfer: Accelerating generative LLM serving with speculative inference and token tree verification. arXiv:2305.09781.
- Yan, M., et al. (2023). Decoding Speculative Decoding. University of Wisconsin-Madison.
- Liu, X., et al. (2025). Speculative Decoding: Performance or Illusion? arXiv:2601.11580.
- Li, Z., et al. (2024). EAGLE-3: Efficient Training and Inference for Feature-Level Speculative Decoding. Technical Report.
- Chen, W., et al. (2025). Decentralized Speculative Decoding. arXiv:2511.11733.
Technical Glossary:
- Autoregressive Generation: Sequential token-by-token text generation where each token depends on previous tokens
- KV Cache: Key-Value cache storing intermediate attention computations to avoid redundant calculation
- Speculative Sampling: Modified rejection sampling algorithm ensuring output distribution equivalence
- Tree Attention: Modified attention mechanism allowing parallel verification of multiple candidate sequences
- Token Acceptance Rate (TAR): Average number of draft tokens accepted per verification step
This article represents the state-of-the-art in Speculative Decoding as of early 2025, incorporating findings from the latest academic research and production deployments. For implementation-specific questions, consult the latest documentation for frameworks such as vLLM, TensorRT-LLM, or Hugging Face TGI.
